
Converting Unicorn from Java to Kotlin
Unicorn started as quite a straightforward service, and its job was to download CSV data from FTP of one of our clients, parse it, process it into a format that Daisy understands and send it via RabbitMQ. The client could then view their internal ads data in our platform. This was implemented in Java 8 because it is lingua franca of our team. The application was based on Spring Boot, MongoDB and was deployed in a docker container on one of our servers. After that, we added the same kind of integration for another client and then an offline conversion integration for yet another client. Offline conversions are in-store purchases (or other events) that a client collects into some kind of a data store (FTP, SFTP, etc.) and we upload it for them onto Facebook. Facebook then attributes this data to ads.
At that point, we had 3375 lines of reasonably well written Java 8 code, and we realized that while the codebase is relatively small, we could experiment with it a bit. So we decided to try to re-write the complete service into Kotlin, and this is how we did it. Firstly, we used IntelliJ IDEA to convert each Java file into a Kotlin file. This resulted in a really rough Kotlin source code that would not even compile (not by a longshot), but overall the result was rather good. Secondly, we went over all the source files and fixed the compilation errors. After that, the main bulk of the work was behind us, and we just needed to fix the tests (which required some additional libraries like mockito-kotlin ). To further decrease the number of dependencies and the size of the source code, we removed some unnecessary libraries:
- lombok, which was used to generate getters, setters, equals, and hashcode and so on. Kotlin has this functionality built-in, so it is not needed.
- apache-commons was used to test strings ( isEmpty , isNull ) and booleans ( isTrue , isNotTrue etc). Kotlin again already offers these as extension functions.
- Remove all !! operators
- Replace single-line collection creation statements (like Arrays.asList ) with Kotlin collections ( setOf , listOf , mapOf )
- Replace streams with Kotlin functional-style syntax ( list.stream().map -> list.map { ... } ) wherever appropriate
- Replace map.put(key, value) with map[key] = value
- Replace string concatenation with string interpolation
- Treat if, try and other statements as expressions when useful (e.g. replace try { return ... } with return try { ... } )
The last step was to test the application in runtime, which discovered one bug - we needed to use the Jackson-module-kotlin library because Jackson did not correctly serialize and deserialize Kotlin classes without it. Moreover, that's it, after all that, the application ran without any visible issues. Converting the application into Kotlin reduced the number of lines to 2194.
Downloading Facebook Insights API with Kotlin
When we finished converting Unicorn into Kotlin, we started working on the implementation of Facebook Insights. If you have ever worked with Facebook Insights API, you know the API is very complicated. The recommended approach is to try a synchronous request to the API to retrieve a set of ad IDs that had any impressions for a given time range. If that fails, you should retry with an asynchronous request (which is complicated itself). Once you get the ids, you need to request each ad id to retrieve its statistics. However, there are many complications with this approach. Firstly, there is a rather complicated limiting mechanism in the API so that you could not overload the API. Secondly, if you want to download unique statistics (e.g., unique_clicks ), you need to do it for upper ad layers (Ad Sets and campaigns) separately and also for all the time ranges you want, because it cannot be aggregated from single-day single-layer data.
Now imagine you have hundreds of accounts and you want the data to be as fresh as possible. Facebook refreshes the data every 20 minutes and even data that is as old as 28 days can change because of attribution windows. If you have 1000 accounts and on average, they each contain 100 active ads per day, 500 active ads per 28 days, this gives you roughly 100 thousand requests per minute. Fortunately, FB allows you to send requests in batches, so you don't have to do too many I/O operations, but it does not have any effect on FB limits, so you still have to deal with those the same way regardless of batching.
This amount of I/O requires much parallelism, and Kotlin is well suited for that. However, so is Java especially since adding completable futures that allow you to create an asynchronous pipeline for chaining smaller parts of your business logic together, avoiding too many synchronization sections in the process. So what extra features does Kotlin have compared to Java regarding this? When we started working on this project, we could not see how complicated working with the Facebook Insights API was going to be. We wanted a clean, well-written application that does its single job well. While this part of the service wasn't running in production, it was easy to follow such a principle. When we started easing the application into production gradually, we were discovering and fixing new bugs, some pretty big that would have required quite a lot of changes. Unfortunately, some of these changes would have significantly diminished some of the principles we started with.
One of the major problems was that making so many API requests to the Facebook API triggers the rate limiting mechanism very often. Facebook returns the API load in the headers, but reacting to the values turned out nearly impossible because, due to the vast amount of Facebook API requests, it is not possible to throttle the request rate fast enough (latency of just tens of milliseconds is too late). So instead, we decided to wait with each thread that sends the API request and after some time, re-attempt it. Also, here is the problem, waiting is a blocking operation, so it blocks the whole thread and eventually when all threads are blocked, the entire application is blocked and slows down to a crawl.
The solution is to create objects that represent work (so, e.g. worker or task), and you monitor their life-cycle, when they get stuck (e.g., hit a rate limit), you remove them from a thread for some time (effectively pausing them) and in the process, you release the thread for another worker/task. Unfortunately, this requires a lot of boilerplate, we already implemented this pattern in our old service that handled Facebook insights and we wanted to avoid it as the primary reason for implementing it in Unicorn was to improve it, not just copy it.
Kotlin Co-routines to the Rescue
To solve the issue as neatly as possible, I was searching around the web for a non-blocking way in Kotlin to pause the thread, and I came across an article about an experimental feature in Kotlin called co-routines. We promptly realized this could be the answer to our problem and while it was just an experimental feature, we still wanted to give it a try. The great thing about Kotlin co-routines is that they are effortless to use, we just needed to defer code that we wanted to run in a co-routine with the async function, use the delay co-routine function instead of Thread.sleep and finally block the execution until all the co-routines finish with runBlocking { it.await() } . Here is a simplified example: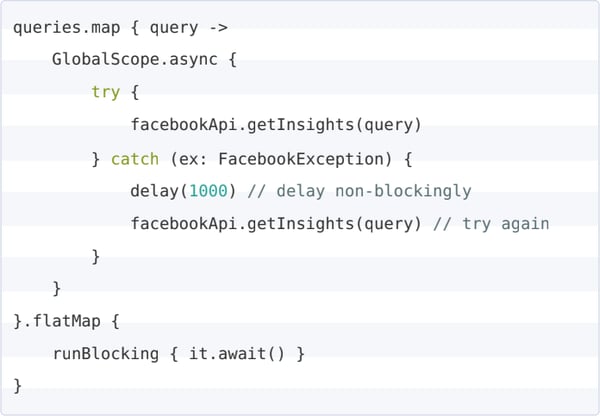
After we deployed this change into production, it immediately solved our problem, and we were finally able to fully utilize the new much more reliable way of downloading Facebook insights.
Conclusion
Kotlin is a new language, and so it brings many questions about its viability for production use. Using it in production in business-critical applications certainly has some risks, but as it compiles into Java bytecode, it cooperates very well with Java libraries and tooling and is very easy for Java developers to pick up, I believe the risks are greatly diminished.
Benefits of using Kotlin
- Reduction of codebase size
- Improvement of overall readability of the code
- Facilitates solving non-trivial software architecture problems
- Migration to Kotlin is relatively easy for smaller projects
In the article, we have seen how Kotlin can reduce the codebase size, increase overall readability of the code and also solve some non-trivial problems that would otherwise be difficult to deal with. We have also shown how it can be relatively simple for smaller projects to migrate to Kotlin, and while it is undoubtedly quite complicated especially for larger projects, it's probably possible.
In the following months, JetBrains is going to release Kotlin 1.3, so the language seems to be evolving further. According to pusher.com, the adoption of Kotlin is also increasing, so the future for Kotlin at least so far looks bright. Many people, especially young engineers, view Kotlin very positively so it really might be a good idea to get ahead of the curve and try to opt for the language for some smaller or even larger projects. One day it might turn out to have been a great decision.


